今回は話者識別(Speaker Identification)をやってみます。
同じ話者認識(Speaker Recognition)の分野では、他には話者照合(Speaker Verification)というのがあるみたいです。
漢字、英語の意味通り、複数の話者のデータから、誰の声かを識別するのが今回行う話者識別になります。
今回は音声からLPC解析を用いて特徴抽出を行い、SVMという簡単な機械学習を用いて分類をしてみました。
音声は日本声優統計学会というところからお借りしました。
https://voice-statistics.github.io/
土谷麻貴さん、上村彩子さん、藤東知夏さんがテキストを読み上げている総長2時間のデータセットです。
それぞれ3人について通常、喜び、怒りのデータセットがあります。
今回はそれぞれの通常音声を用いて3人の識別を試しました。
librosaによるLPC解析
人間の声道特性を表すスペクトル包絡を求める手法として、ケプストラム解析とLPC解析が存在します。
今回はLPC(Linear Predictive Coding)解析を使っていきます。
LPC係数とは、LPC解析によってスペクトル包絡を求める際に、フィルタに用いる係数になります。
こちらの係数にも声道特性が含まれるため、この係数を用いて分類を行おうと考えました。
librosaはpythonで音を扱うためのライブラリで、pipでインストールできます。
pip install librosa
今回用いるのはlibrosa.lpc関数です。解析する信号と次数を渡すと係数が返ってきます。
import librosa lpc = librosa.lpc(wave, 20)
次数を20にして求めたLPC係数の例が次のグラフになります。
次数は20程度がよく用いられるっぽいです。
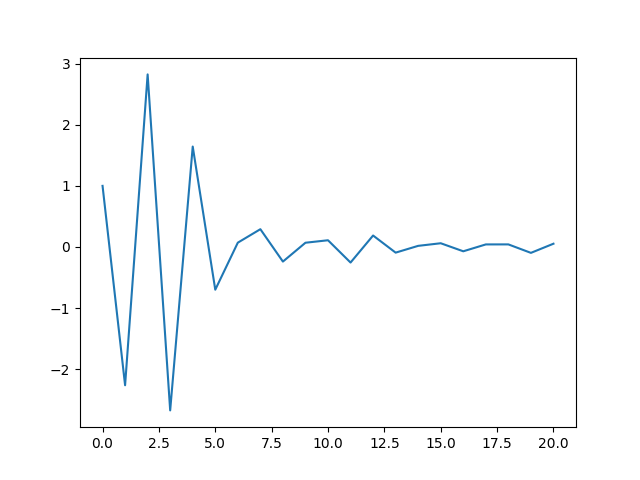
SVMによる話者識別
3人の音声について、それぞれランダムに0.5秒ずつ取り出して、LPC係数を求めるのを1000回ずつ行います。
つまり、合わせて3000のデータを抽出します。
今回はそのうち2700で学習を行い、300で精度を評価しました。
SVMにLPC結果の配列と、話者ラベルの配列を与えて学習を行います。
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(LPC_list, label_list,test_size=0.1) #LPC係数とラベル(話者)を分割
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy score : ", accuracy_score(y_test, y_pred))
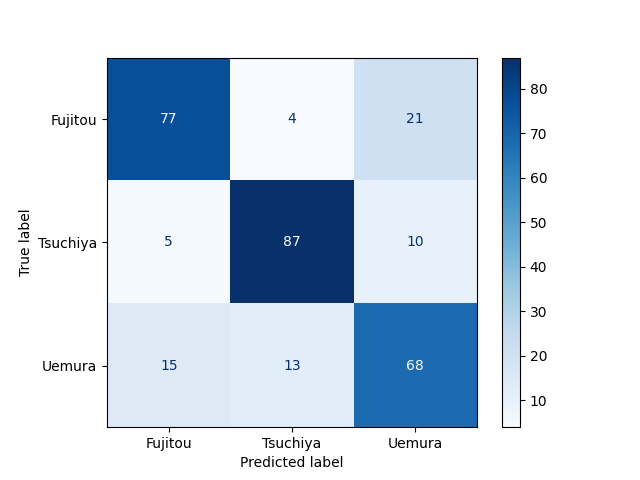
accuracy scoreは0.76となりました。
ランダムで選ぶ(=33%)よりはマシですが、まだまだ改善の余地がありますね。
混合行列は下の図の通り。声似てるかどうかが分かりますね。
今回は20次元のLPC係数に対してSVMを用いましたが、次元数や学習方法を改善することで精度は向上すると思います。
また、音からの特徴抽出手法については、LPC係数以外の手法も試してみたいです。
例えば、ケプストラムを用いる手法や、LPC係数の時間変化を用いる手法も有効だという文献があるみたいです。

コメント