以前、LPC解析によって音声の特徴を抽出してSVMによって識別する方法で話者識別をしてみました。
今回は定Q変換による時間周波数解析で特徴抽出を行い、CNNで分類をしていきます。
tensorflowのチュートリアルでも時間周波数解析(STFT)で特徴抽出をしてCNNで分類をしているものがありました。
時間周波数解析➡機械学習で処理するのがよくある手法みたいですね。
今回も音声は日本声優統計学会というところからお借りしました。
https://voice-statistics.github.io/
土谷麻貴さん、上村彩子さん、藤東知夏さんがテキストを読み上げている総長2時間のデータセットです。
それぞれ3人について通常、喜び、怒りのデータセットを用いました。
librosaによる定Q変換
pythonで時間周波数解析~定Q変換~で紹介した手法を用いて、音声から特徴を抽出します。
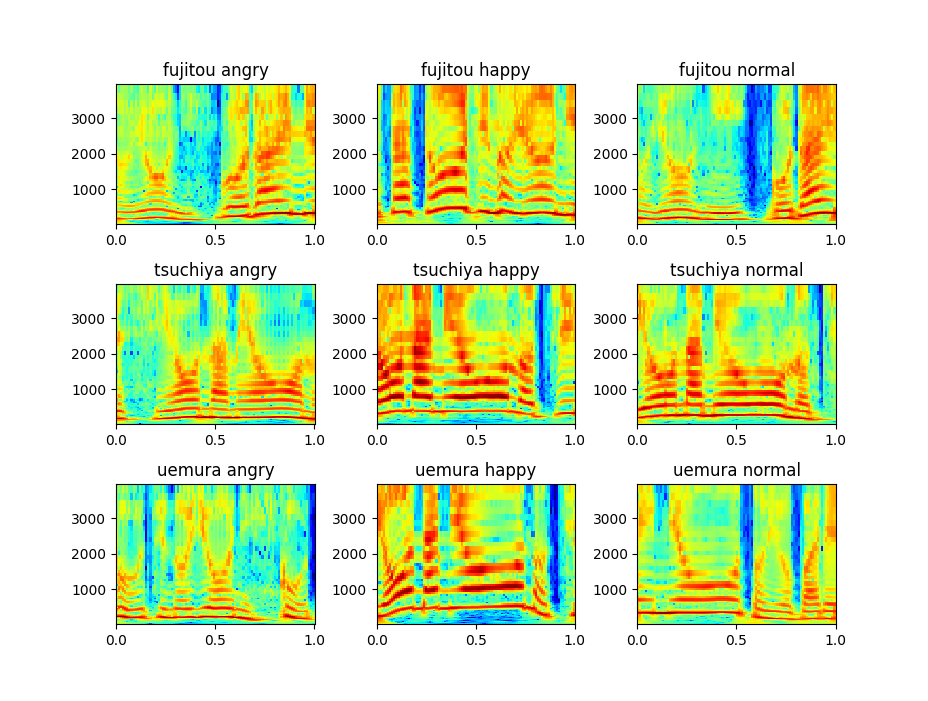
3人の話者×3つの感情(通常、喜び、怒り)で9つの分類を行います。
それぞれプロットした結果が以下のグラフです。
これだけでは何も分からないですね。
CNNによる話者識別
それぞれランダムに1秒ずつ取り出して、定Q変換するのを500回ずつ行います。
出力は84×94の2次元配列になります。
CNNのライブラリにはTensorFlowを用いています。
プログラムは以下の通り。
ほとんど画像分類で使うCNNと同じです。
import tensorflow as tf
if __name__ == "__main__":
# X_train, X_test, y_train, y_testを読み込む
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Reshape((84, 94, 1), input_shape=(84, 94)))
model.add(tf.keras.layers.Conv2D(64, (5, 5), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.2))
model.add(tf.keras.layers.Dense(9, activation='softmax'))
model.compile(optimizer='Adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, validation_data=(X_test, y_test))
model.evaluate(X_test, y_test, verbose=2)
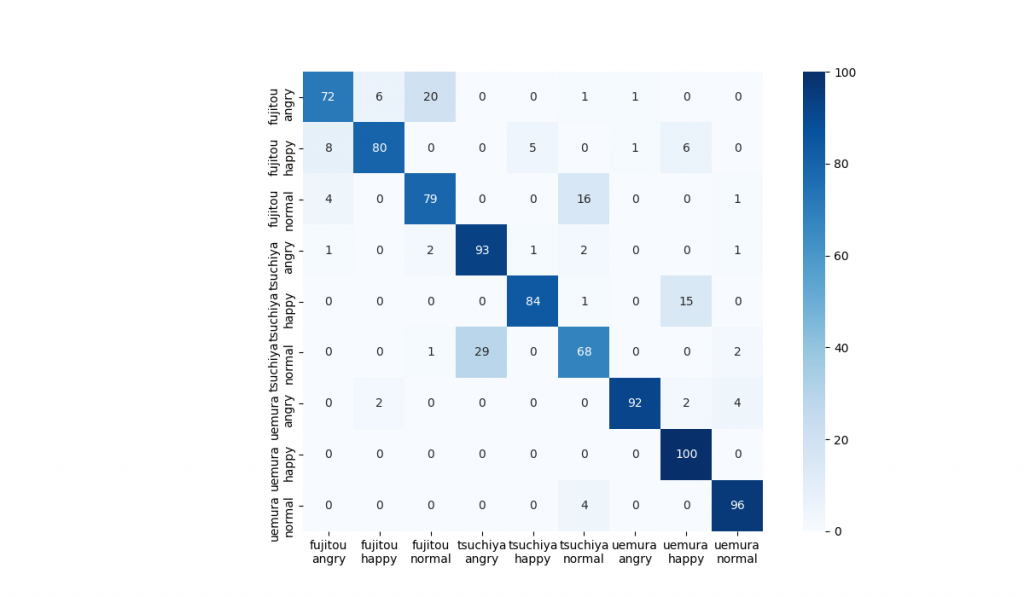
精度は0.764でした。?
分類結果は下のグラフ。左上からの対角線上にない部分で色が濃い部分が誤識別が多いところになります。
土谷さんが普通の声と怒っている声、土谷さんが喜んでいる声と上村さんが喜んでいる声が似ているらしいです。
上村さんは感情が声に乗りやすいという見方もできそうです。
今回は初めてTensorFlowというライブラリを使いましたが、とても簡単にCNNを実装できました。
パラメータの調整はしていない(よく分かっていない)のですが、色々調整するとより精度が上がると思います。
コメント